

LLM과 RAG는 자연어 처리(NLP) 분야에서 사용되는 두가지 다른 접근 방식이다.
최근 LLM과 함께 RAG 기술이 각광 받고 있는데 LLM과 RAG가 무엇인지, 두 기술이 어떻게 결합되어 사용되는지 알아보겠다.
RAG (Retrieval-Augmented Generation)
- RAG는 정보 검색(IR)과 생성 모델을 결합한 아키텍처로, 특정 쿼리에 대한 응답을 생성할 때 관련 정보를 검색하여 그 결과를 생성 과정에 통합한다.
- 이 방법은 주어진 질문에 대한 답변을 생성하기 전에, 관련된 문서나 데이터를 검색하여 그 정보를 기반으로 답변을 생성하는 방식으로 작동한다.
- RAG는 생성 모델에게 검색된 정보를 추가적인 컨텍스트로 제공함으로써, 더 정확하고 상세한 답변을 생성할 수 있도록 한다.
- 이 접근 방식은 특히 정보가 많거나 특정한 사실을 요구하는 질문에 유용하다.
LLM (Large Language Models)
- LLM은 매우 큰 양의 텍스트 데이터에서 학습된 모델로, GPT-3와 같은 모델이 이에 속한다.
- 이러한 모델들은 수십억 개의 파라미터를 가지고 있으며, 다양한 언어 작업에 대해 뛰어난 성능을 보인다.
- LLM은 주어진 프롬프트에 대해 연관된 텍스트를 생성할 수 있으며, 그 범위는 단순한 텍스트 생성에서부터 질문에 대한 답변, 문서 요약, 번역 등 다양하다.
- LLM의 핵심 강점은 광범위한 지식과 데이터에서 학습한 능력으로, 특정한 데이터 검색 없이도 다양한 질문에 답변할 수 있다는 것이다.
RAG와 LLM의 통합 구조
ChatGPT의 경우 2021년 9월까지의 데이터를 기준으로 학습했다.
그렇지만 21년 9월 이후의 정보에 대해서도 질문에 대한 답을 생성하는데, 종종 정확하지 않은 답변을 생성한다. 이를 Hallucination(환각)이라고 부른다.
환각이 발생하는 이유는 ChatGPT에서 사용한 GPT 모델이 "Auto-regression LLM"이기 때문이다.
Auto-regression LLM은 이전 단어를 보고 가장 높은 확률의 단어를 다음 단어로 예측하므로 단어의 순서에 따라 얼마든지 다른 답변을 출력할 수 있다.
즉, 학습한 정보에 해답이 없어도 학습한 방식을 기준으로 확률적으로 가장 그럴듯한 응답을 생성한다.
그러나, 최신의 정보를 기준으로 정확한 답변을 전달해야 하는 요구사항이 있는 경우, LLM을 재학습하지 않고 RAG를 사용해서 언어 모델이 정확한 응답을 하게 할 수 있다.
RAG를 사용하면, 사용자 질문에 해당되는 응답 정보의 문서 정보를 미리 저장한 Vector Score에서 검색하고, 그 검색 결과에 해당되는 본문을 LLM에 전달하여 LLM이 생성한 본문의 요약된 결과를 사용자에게 응답하는 방식이다.
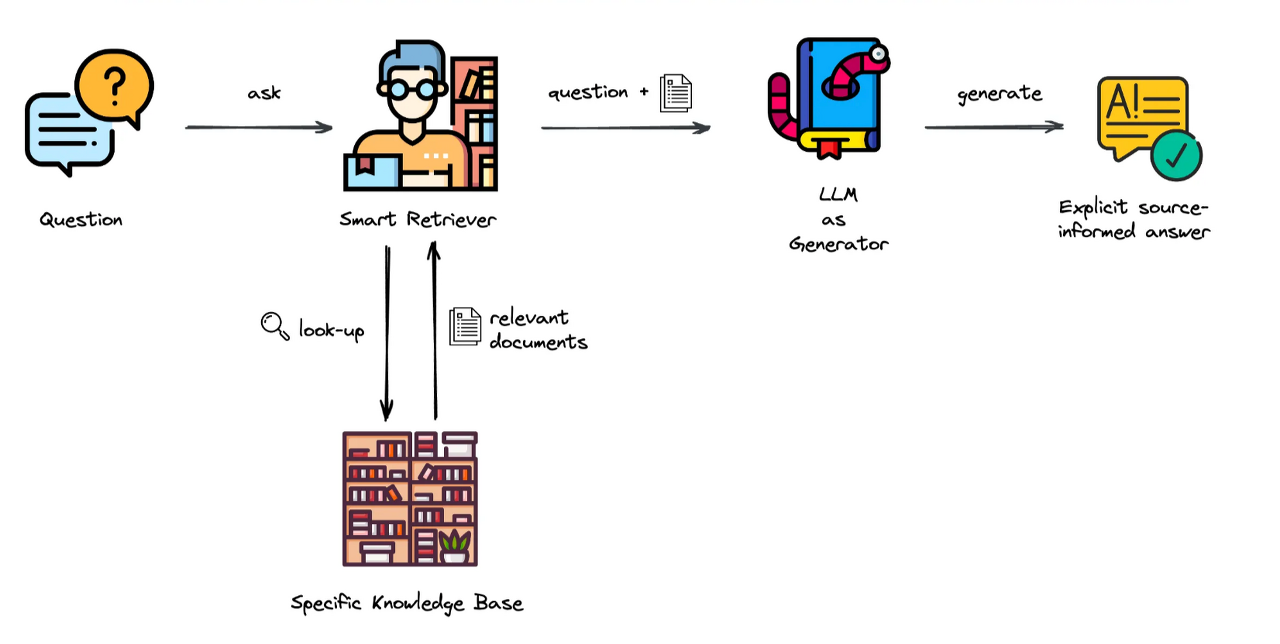
다음은 RAG와 LLM를 통합하여 어떻게 응답을 이끌어 내는지에 대한 이미지이다.
앞서 RAG는 정보를 미리 저장해 둔 특정한 데이터베이스를 이용하는 방식이라고 했다.
우리가 어떠한 정보를 알고 싶은데, 도서관에서 해당 정보를 찾는다고 가정해보자. 이때, RAG는 도서관으로 LLM은 책의 작가로 비유 가능하다.
사용자가 "피타고라스의 정의는 무엇인가요 ?" 라는 질문을 던진다고 해보자. RAG(도서관) 내부의 문서 검색기는 도서관의 수많은 책 중에서 이 질문에 대한 정보를 담고 있는 책을 찾아낼 것이다. 이후 LLM(작가)는 이 책의 정보를 이용해 사용자에게 답변한다.
RAG의 오프라인 작동 방식
RAG는 기본적으로 외부의 정보 소스를 참조하여 작동하는 구조이므로 인터넷 연결이 필요하다.
기업의 경우 보통 내/외부 망이 구분되어 있으며 기업의 데이터베이스를 활용하고 싶은 경우도 많다.
RAG는 인터넷 연결 없이도 작동할 수 있는 구성 또한 가능한데 이를 위해 내부 데이터베이스를 활용하거나 모든 필요한 데이터를 로컬에 저장하고 RAG가 해당 로컬 데이터베이스를 사용하도록 설정할 수 있다.
이 방식을 이용하여 RAG는 업무 환경에서 데이터 검색과 문서 생성을 향상하는데 유용하게 사용될 수 있다.
RAG 동작 단계
RAG가 특정 질문이나 프롬프트에 대해 정보를 검색하고, 그 정보를 바탕으로 답변을 생성하는 단계는 크게 세 부분으로 나눌 수 있다.
1. 검색 단계 (Retrieval Phase)
목적: 사용자의 질문이나 프롬프트에 가장 관련 있는 정보나 문서를 검색하는 것이 목적이다.
동작: 사용자로부터 입력받은 질문이나 프롬프트를 기반으로, 대규모의 문서 데이터베이스에서 관련 정보나 문서를 검색한다. 이 검색 과정은 종종 키워드 검색, 벡터 검색, 또는 다른 고급 정보 검색 기술을 사용하여 최적의 결과를 찾아낸다.
2. 통합 단계 (Integration Phase)
목적: 검색된 정보를 생성 모델의 입력으로 통합하여, 이를 통해 생성될 답변의 품질을 향상시키는 것이다.
동작: 검색 단계에서 찾아낸 정보나 문서는 생성 모델에 전달되기 전에 적절히 가공된다. 이 정보는 생성 모델이 참조할 수 있는 형태로 변환되어, 생성 모델이 해당 정보를 기반으로 답변을 생성할 수 있도록 한다. 이 과정에서는 검색된 정보의 중요한 부분을 강조하거나, 질문과 관련된 컨텍스트를 제공하는 방식으로 정보를 통합할 수 있다.
3. 생성 단계 (Generation Phase)
목적: 검색하고 통합된 정보를 바탕으로 사용자의 질문이나 프롬프트에 대한 답변을 생성하는 것이다.
동작: 통합된 정보를 입력으로 받은 생성 모델(예: GPT-3)은 이를 기반으로 관련 있는 답변을 생성한다. 이 단계에서 모델은 검색된 정보와 자체 학습된 지식을 조합하여, 질문에 대한 정확하고 상세한 답변을 생성하게 된다. 생성된 답변은 사용자에게 제공되기 전에 필요한 경우 후처리 과정을 거친다. RAG의 이러한 동작 단계는 정보 검색과 생성 모델의 강점을 결합하여, 특정 질문에 대해 더 정확하고 상세한 답변을 생성할 수 있도록 한다. 이 과정을 통해 RAG는 단순한 텍스트 생성을 넘어서, 정보에 기반한 정교한 답변 생성에 있어서 중요한 역할을 하게 된다.
RAG와 Fine Tuning 비교
RAG는 환각 현상의 해결 방안 중 하나인 파인 튜닝에 비해 이점이 있다.
파인 튜닝은 모델에 특정 분야의 데이터를 추가로 훈련시켜서 특정 도메인에 대한 전문성과 정확도를 높이는 기술이다.
그러나 이런 추가적인 훈련을 위해 막대한 데이터 학습 비용이 들어갈 뿐만 아니라 해당 분야의 발전에 따라 지속적으로 업데이트해야 한다는 부담이 크다.
반면 RAG는 검색 기능을 통해 AI가 답변을 생성하기 전 외부의 신뢰할 수 있는 데이터를 참조해서 답변의 정확성을 높이는 방식이기 때문에 훈련 부담이 없고 모델 자체를 업데이트할 필요가 없다. 모델 자체의 전문성은 떨어지지만 답변을 전문적인 외부 자료를 통해 한번 더 체크하기 때문에 환각 현상을 줄일 수 있는 것이다.
마치며
LLM과 이를 활용한 ChatGPT에 대한 관심이 폭발한지 얼마되지 않아 RAG라는 추가 개선 방법이 등장했고, 이에 대한 기업들의 반응도 뜨거워지고 있다.
IT 네이티브한 기업이 아니라면, 특히 기업 내부에 전문 AI 조직이 없다면, LLM을 기업 내부에서 직접 파인튜닝하여 사용하기에 어려움이 있다. 또한, 파인튜닝을 한 모델로 개발한 기능이 추가적인 비즈니스 가치 창출로 이어질 확신이 없다면 파인튜닝에 들어가는 큰 비용을 선뜻 감당하고자 할 기업은 드물 것이다.
하지만, 최근에는 RAG 기술을 통해 그 비용을 절감하고 빅테크 기업에서 제공하는 LLM 모델을 활용할 수 있기 때문에 많은 전통 기업들도 하나 둘 LLM에 관심을 기울이는 것이 아닐까 한다.
'Study > Study' 카테고리의 다른 글
| [Cloud FinOps] 17장. 비용 관리 자동화 (0) | 2024.02.08 |
|---|---|
| [Cloud FinOps] 16장. 메트릭 기반 비용 최적화 (0) | 2024.02.07 |
| [Cloud FinOps] 14장. 예약 인스턴스와 약정 사용 할인 전략 (0) | 2024.02.06 |
| [Cloud FinOps] 13장. 예약 인스턴스와 약정 사용 할인으로 비용 절감 (0) | 2024.02.04 |
| Bastion Host를 왜 ? 써야할까 ? (0) | 2024.01.05 |
영차영차 성장 블로그
포스팅이 좋았다면 "좋아요❤️" 또는 "구독👍🏻" 해주세요!
![[Cloud FinOps] 14장. 예약 인스턴스와 약정 사용 할인 전략](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2Fbb9AfS%2FbtsEoot1TsA%2FAAAAAAAAAAAAAAAAAAAAAHom4GviNXttisBdWOzAUhiEFGwRkm5N-Y0VrLtzlPit%2Fimg.jpg%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1764514799%26allow_ip%3D%26allow_referer%3D%26signature%3DMtarDsd9jFckOOiFPXHax9Yskb0%253D)
![[Cloud FinOps] 13장. 예약 인스턴스와 약정 사용 할인으로 비용 절감](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2F0P9Zb%2FbtsEpqE7O9o%2FAAAAAAAAAAAAAAAAAAAAAKrqRbJJt-0EnnZFn-fO1FITVl_QDtknlq2hMM2o60QN%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1764514799%26allow_ip%3D%26allow_referer%3D%26signature%3DA9IS04lVoxVkrIMD5GUXa0ZfSIE%253D)