

클라우드의 핵심, 가상화와 클라우드 관리 스택 온프레미스와 프라이빗 클라우드의 가장 큰 차이점은 클라우드의 핵심 능력을 보유하고 있는지의 여부다. 여기서 말하는 클라우드의 핵심 능력은 '신속함'이다. 기업의 서비스에 사용자가 몰리면 프라이빗 클라우드는 해당 서비스를 위한 인프라를 증설해 빠르게 서비스를 안정화시킬 수 있다. 반면 온프레미스는 이것이 대단히 어렵다. 인프라를 새로 주문하고 이를 설치해 서비스에 연결할 때까지(보통 1~2주) 서비스를 안정시킬 수 없다. 이러한 신속함을 갖기 위해 프라이빗 클라우드는 두 가지 핵심 능력을 갖추고 있어야 한다. 첫번째는 '가상화'이다. 가상화는 클라우드를 지탱하는 핵심 기술이다. 가상화란 네트워크 장비, 서버, 스토리지(저장 장치) 등 데이터 센터 내의 인프라 ..

Scale Up 서버의 자원이 부족해 서버의 스펙을 상승시키는 것을 말한다. 하나의 서버의 능력을 증강하기 때문에 수직 스케일링(Vertical Scaling)이라고도 한다. 즉, 기존의 하드웨어를 보다 더 높은 사양으로 업그레이드 하는 것을 말한다. 예를 들어 AWS에서 스펙이 더 좋은 인스턴스 타입으로 교체하는 것과 같다. Scale Out 서버의 스펙을 상승으로는 한계가 있어 효율이 떨어지는 시점이 있다. 기존의 서버와 같은 사양의 서버 대수를 증가시키는 방법으로 처리 능력을 향상시키는 것을 말한다. 이 방식을 Horizontal scaling이라고도 하며 확장이 Scale Up보다 다소 유연하다. 1의 처리 능력을 가진 서버에 동일한 서버 4대를 추가하여 총 5의 처리 능력을 만드는 것이다. → ..

서론 경사 하강법과 같이 결과를 내기 위해서 여러번의 최적화 과정을 거쳐야 하는 알고리즘을 iterative 하다고 한다. 반복해서 많은 양의 데이터 학습을 진행할 때, 보통 한번에 최적화된 값을 찾기 어렵다. 머신러닝에서는 최적화(optimization)를 하기 위해 여러번의 학습 과정을 거친다. 또한 한번에 모든 양의 데이터를 넣지 않고 데이터를 나눠서 학습시키는데 이때 등장하는 개념이 에폭(epoch), 배치 사이즈(batch size), 반복(iteration)이다. 전체 개념에 대한 개략적인 내용이다. 에폭(epoch)이란 ? 한번의 에폭은 전체 데이터셋에 대해 forward pass/backward pass 과정을 거친 것을 말한다. 즉, 전체 데이터셋에 대해 한번 학습을 완료한 상태를 의미힌..

역전파 알고리즘이란 ? 역전파 알고리즘이란 인공 신경망을 학습시키기 위한 일반적인 알고리즘 중 하나이다. Perceptron(퍼셉트론) : 초기 인공 신경망 모델 input → output까지 가중치를 업데이트하면서 활성화 함수(sigmoid, rule 등)를 통해 결과값을 냈다면, 역전파 알고리즘은 그렇게 도출된 결과값을 통해 다시 output에서 input까지 역방향으로 가면서 가중치를 재업데이트를 해주는 방법이다. 역전파를 하는 이유는 무엇일까 ? 수치 미분을 통해 신경망을 갱신하려면, 미분 과정에서 delta 값을 더한 순전파를 몇번이고 다시 행해야 한다. → 즉, 연산량이 많다. 더 복잡하고 더 큰 규모의 딥러닝에 대해 순전파로 몇번이고 학습을 수행하면서 적절한 가중치 값을 찾고자 한다면 매우매..
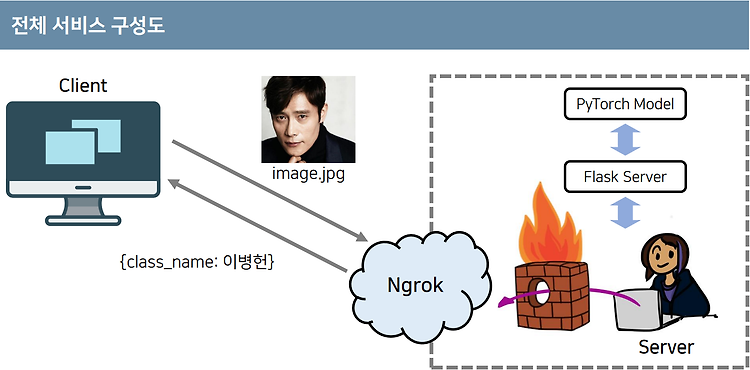
해당 글은 유튜브 나동빈 채널의 영상을 보고 정리한 글입니다 !! https://www.youtube.com/watch?v=Lu93Ah2h9XA 서비스 소개 다양한 이미지가 들어왔을 때 이미지가 어떤 클래스인지 즉, 어떤 사람인지로 분류 가능 일반적인 인공지능 서비스 개발 과정 1. 학습에 필요한 데이터를 수집하고 가공 2. 가공된 학습 데이터를 이용해 적절한 인공지능 모델을 학습 3. 학습된 모델을 배포해 어플리케이션에서 이를 활용 데이터 수집 → 데이터 가공 → 모델 학습 → API 배포 ex) 인공지능 모델 학습 이후 안드로이드 App, 게임, Web 등에 연동하여 인공지능 서비스 제공 가능 개발 방법 구글 Colab을 이용하여 전이 학습(Transfer Learning)을 활용한 분류기 제작 1...

🚀 Embedding이란 ? NLP 분야에서는 Embedding 과정을 거치는데 Embedding이란 자연어를 기계(컴퓨터)가 이해할 수 있는 형태(숫자, Vector)로 바꾸는 과정 전체를 말한다. 임베딩은 대표적으로 아래 3가지 역할을 한다. 1. 단어/문장 간 관련도 계산 2. 단어와 단어 사이의 의미적/문법적 정보 함축(단어 유추 평가) 3. 전이학습(Tansfer Learning) → 좋은 임베딩을 딥러닝 모델 입력값으로 사용하는 것 🚀 BERT의 내부 동작 과정 🚀 Input BERT의 Input과 Output은 위와 같다. 3가지의 요소를 입력해줘야 한다. Token Embedding : 각 문자 단위로 임베딩 Segment Embedding : 토큰화 한 단어들을 다시 하나의 문장으로 만드..