
BERT의 동작 과정
🚀 Embedding이란 ?
NLP 분야에서는 Embedding 과정을 거치는데
Embedding이란 자연어를 기계(컴퓨터)가 이해할 수 있는 형태(숫자, Vector)로 바꾸는 과정 전체를 말한다.
임베딩은 대표적으로 아래 3가지 역할을 한다.
1. 단어/문장 간 관련도 계산
2. 단어와 단어 사이의 의미적/문법적 정보 함축(단어 유추 평가)
3. 전이학습(Tansfer Learning) → 좋은 임베딩을 딥러닝 모델 입력값으로 사용하는 것
🚀 BERT의 내부 동작 과정
🚀 Input

BERT의 Input과 Output은 위와 같다. 3가지의 요소를 입력해줘야 한다.
- Token Embedding : 각 문자 단위로 임베딩
- Segment Embedding : 토큰화 한 단어들을 다시 하나의 문장으로 만드는 작업
- Position Embedding : 토큰 순서대로 인코딩
Token Embedding
Word Piece 임베딩 방식 사용, 각 Char(문자) 단위로 임베딩을 하고,
자주 등장하면서 가장 긴 길이의 sub-word를 하나의 단위로 만든다.
자주 등장하지 않는 단어는 다시 sub-word로 만든다.
이는 이전에 자주 등장하지 않았던 단어를 모조리 'OOV'처리하여
모델링의 성능을 저하했던 'OOV'문제도 해결 할 수 있다.
Segment Embedding
토큰 시킨 단어들을 다시 하나의 문장으로 만드는 작업이다.
BERT에서는 두개의 문장을 구분자([SEP])를 넣어 구분하고
그 두 문장을 하나의 Segment로 지정하여 입력한다.
BERT에서는 이 한 세그먼트를 512 sub-word 길이로 제한하는데,
한국어는 보통 20 sub-word가 한 문장을 이룬다고 하며
대부분의 문장은 60 sub-word가 넘지 않는다고 하니
BERT를 사용할 때, 하나의 세그먼트에 128로 제한하여도 충분히 학습이 가능하다고 한다.
Position Embedding
Self Attention은 입력의 위치를 고려하지 않고 입력 토큰의 위치 정보를 고려한다.
Position encoding은 Token 순대로 인코딩 하는 것을 뜻한다.
우선 Segment embedding을 위해 문장을 BERT의 입력 형식에 맞게 변환시킨다. 문장의 시작은 [CLS], 문장의 끝은 [SEP]으로 표시한다.
두번째로는 한 문장에 있는 단어들에 대해 tokenization을 진행한다.
예를 들어 '우리들'이라는 단어의 경우 '우##', '#리#', '##들'로 tokenization을 진행한다.
이러한 방식을 WordPiece 방식이라고 한다.
마지막으로는 Positional embedding인데, 각 token들에 대해 고유의 아이디를 부여한다.
이 부분은 BERT가 학습시에 각 토큰의 위치를 알려주기 위해 필요하다.
token이 존재하지 않는 자리에 한해서는 0으로 채워준다.
🚀 Pre-Training
데이터들을 임베딩하여 훈련시킬 데이터를 모두 인코딩 하였으면, 사전훈련을 시킬 단계이다.
기존의 방법들은 보통 문장을 왼쪽에서 오른쪽으로 학습하여 다음 단어를 예측하는 방식이거나,
예측할 단어의 좌우 문맥을 고려하여 예측하는 방식을 사용한다.
하지만 BERT는 언어의 특성을 잘 학습하도록,
- MLM(Masked Language Model)
- NSP(Next Sentence Prediction)
위 두가지 방식을 사용한다.
1. 다음 문장 예측하기 (NSP, Next Sentence Prediction)
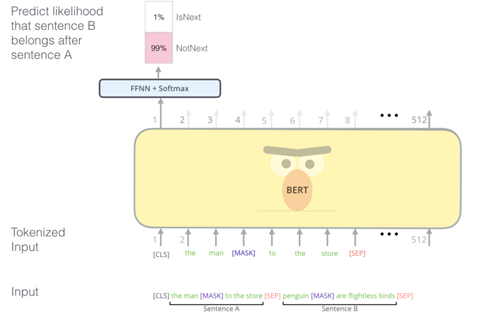
두개의 문장을 준 후에 이 문장이 이어지는 문장인지 아닌지를 맞추는 방식으로 훈련시킨다.
한 문장의 맨 첫번째 토큰인 [CLS]의 출력부에서
입력받은 첫번째 문장과 이어지는지 판별하는 것으로 학습시킨다.
2. 가려진 토큰 예측하기 (MLM, Masked Language Model)
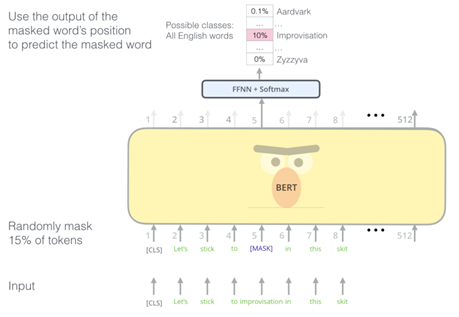
BERT의 토큰 별로 개별적인 Softmax Layer + Fully connected layer를 거쳐
가려진 token에 대해 단어를 예상시키는 학습을 진행한다.
Mask 되지 않은 토큰에 대한 학습까지 병행하며 Mask된 토큰에 대한 예상 학습 정확도를 올린다.
🚀 Transfer Learning
학습된 언어 모델을 전이학습시켜 실제 NLP 수행하는 과정
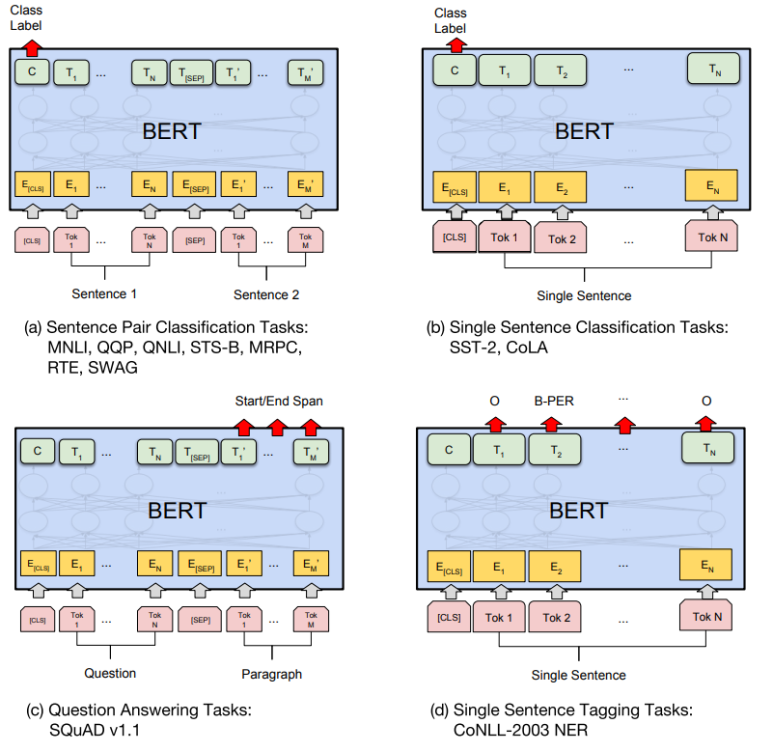
참고
https://brunch.co.kr/@tristanmhhd/12
https://ebbnflow.tistory.com/151
https://blog.naver.com/PostView.naver?blogId=handuelly&logNo=222301180682&parentCategoryNo=&categoryNo=1&viewDate=&isShowPopularPosts=true&from=search
https://moondol-ai.tistory.com/463