3분 만에 만드는 인공지능 서비스 (나동빈 유튜브 강의)
해당 글은 유튜브 나동빈 채널의 영상을 보고 정리한 글입니다 !!
서비스 소개
다양한 이미지가 들어왔을 때 이미지가 어떤 클래스인지 즉, 어떤 사람인지로 분류 가능
일반적인 인공지능 서비스 개발 과정
1. 학습에 필요한 데이터를 수집하고 가공
2. 가공된 학습 데이터를 이용해 적절한 인공지능 모델을 학습
3. 학습된 모델을 배포해 어플리케이션에서 이를 활용
데이터 수집 → 데이터 가공 → 모델 학습 → API 배포
ex) 인공지능 모델 학습 이후 안드로이드 App, 게임, Web 등에 연동하여 인공지능 서비스 제공 가능
개발 방법
구글 Colab을 이용하여 전이 학습(Transfer Learning)을 활용한 분류기 제작
1. Python을 이용해 포털 사이트에서 이미지를 크롤링
2. 전이 학습(Transfer learning)을 이용해 분류 모델을 학습
3. Web API를 개방하여 외부 프로그램이 해당 분류 모델을 이용할 수 있도록 함
학습 방법
일반적으로 사전 학습(Pre-Training)에 사용되는 데이터 셋은
굉장히 큰 규모의 데이터셋으로 많은 클래스를 가지고 있는 경우가 일반적이다.
ex) 이미지넷(ImageNet)과 같은 큰 데이터셋은 실제로 평가 단계에서
천개의 클래스 중 정확한 클래스를 맞추는 방식으로 네트워크를 트레이닝
그렇게 많은 클래스를 가지고 규모가 큰 데이터셋으로 학습이 이루어진 네트워크는
하나의 데이터 즉 이미지가 주어졌을 때 그러한 이미지 안에서
적절한 특징을 추출할 수 있는 형태로 학습이 이루어진다.
그렇기 때문에 사전 학습된 네트워크의 앞쪽 레이어를 잘라서 사용하게 되면
그 자체로 특징 추출기 Feature extracter 로써 사용할 수 있다.
그래서 우리는 사전학습된 네트워크를 가져와서 이렇게 뒤쪽에
학습 가능한 파라미터를 별도로 붙인 뒤에 우리의 Task에 적합하도록 학습을 진행할 수 있다.
바로 이러한 과정을 전이학습(Transfer Learning)이라고 한다.
즉, 우리는 실습을 위해 이미 큰 데이터셋에 대해서 학습이 잘 이루어진 네트워크를 가져온 뒤
우리가 수집한 인물 이미지에 대해서 우리 네트워크를 전이학습 한다.
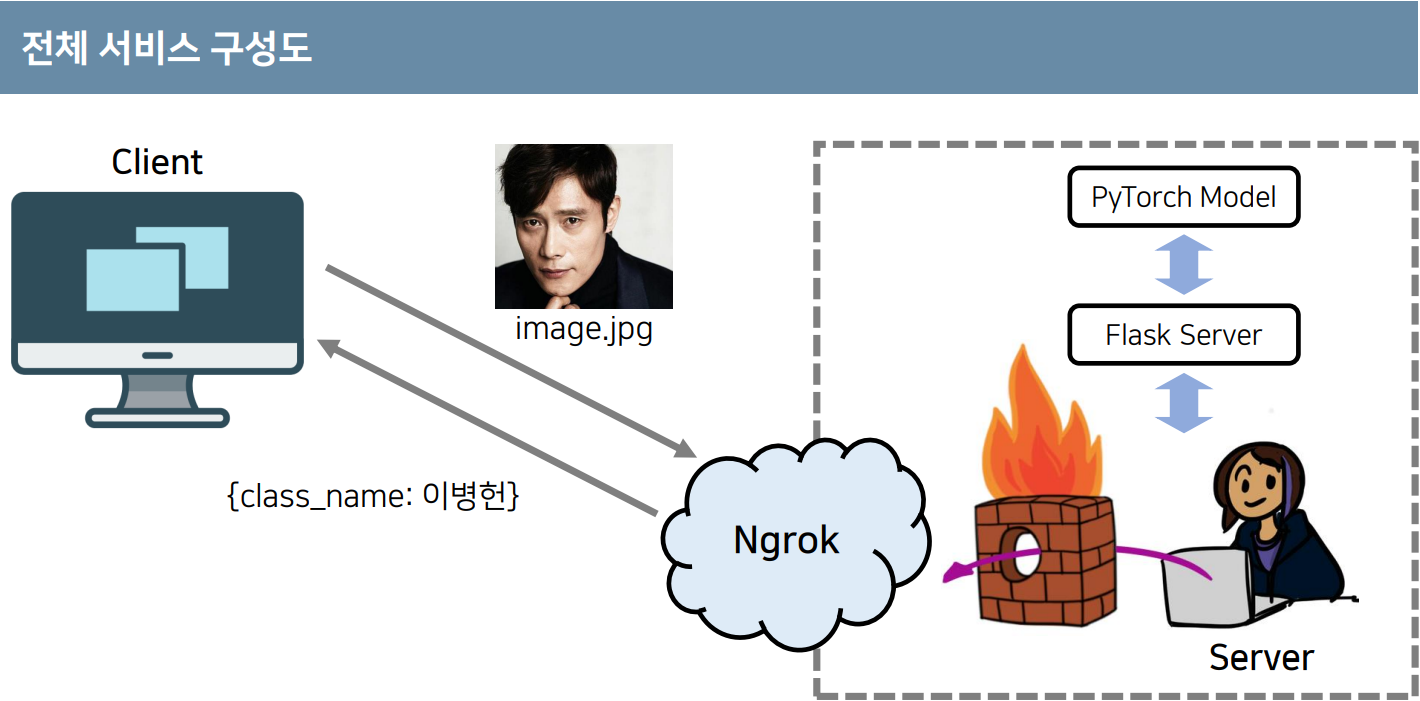
전이학습을 이용해 하나의 모델을 학습하고,
web API를 개방해서 우리가 만든 인공지능 모델을 사용할 수 있도록 한다.
일반적인 사용자는 공인 ip가 존재하지 않을 수 있기 때문에 Ngrok이라는 서비스를 이용해
별도의 공인 주소를 할당받아서 서버를 외부에 개방할 수 있다.
개방된 이후에는 전세계 어디에서나 우리가 만든 서비스에 접근해서
우리의 모델을 사용할 수 있게 된다.
이렇게 인공지능 서비스를 개발한 뒤에는 클라이언트가 우리의 서비스를 호출한다.
한장의 이미지 파일을 업로드했다고 하면 Ngrok을 통해서 서버의 컴퓨터 내부에 이러한 정보가 전달되며
결과적으로 pytorch 모델을 거쳐서 해당 이미지가 어떤 클래스로 분류가 되는지를 구한뒤
해당 이미지의 분류 정보를 얻어서 클라이언트에게 응답한다.
전체 소스 코드 분석
필수 패키지 및 라이브러리 설치
# 한글 폰트 설치하기 (꼭! 설치가 완료되면 [런타임 다시 시작]을 누르고 다시 실행하기)
!apt install fonts-nanum -y
import matplotlib
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
# 한글 폰트 설정하기
fontpath = '/usr/share/fonts/truetype/nanum/NanumBarunGothic.ttf'
font = fm.FontProperties(fname=fontpath, size=10)
plt.rc('font', family='NanumBarunGothic')
matplotlib.font_manager._rebuild()# 필요한 라이브러리 설치하기
!git clone https://github.com/ndb796/bing_image_downloaderbing_image_downloader 라이브러리는 bing이라는 포털 사이트에서 어떠한 키워드를 검색한 뒤에
해당 키워드 검색으로 나온 이미지 데이터를 크롤링해서 다운로드를 받는 라이브러리이다.
우리가 만들 서비스는 각각의 인물들의 이미지를
포털 사이트로부터 자동화해서 다운로드 받을 수 있도록 만들 것이기 때문에
bing_image_downloader 라이브러리 또한 설치해야 한다.
이미지 크롤링
수집한 이미지를 저장하기 위한 폴더를 생성하고, 필요한 함수를 정의한다.
import os
import shutil
from bing_image_downloader.bing_image_downloader import downloader
directory_list = [
'./custom_dataset/train/', # 학습용 데이터
'./custom_dataset/test/', # 검증용 데이터
]
# 초기 디렉토리 만들기
for directory in directory_list:
if not os.path.isdir(directory):
os.makedirs(directory)
# 수집한 이미지를 학습 데이터와 평가 데이터로 구분하는 함수
def dataset_split(query, train_cnt): # query : 각각 인물의 키워드로 별도의 폴더 생성
# 학습 및 평가 데이터셋 디렉토리 만들기
for directory in directory_list:
if not os.path.isdir(directory + '/' + query):
os.makedirs(directory + '/' + query)
# 학습 및 평가 데이터셋 준비하기
cnt = 0
for file_name in os.listdir(query):
if cnt < train_cnt:
print(f'[Train Dataset] {file_name}')
shutil.move(query + '/' + file_name, './custom_dataset/train/' + query + '/' + file_name)
else:
print(f'[Test Dataset] {file_name}')
shutil.move(query + '/' + file_name, './custom_dataset/test/' + query + '/' + file_name)
cnt += 1
shutil.rmtree(query)
각각의 인물에 대한 이미지 크롤링
query = '마동석'
downloader.download(query, limit=40, output_dir='./', adult_filter_off=True, force_replace=False, timeout=60)
dataset_split(query, 30)- download() - bing_image_downloader 라이브러리에 포함된 함수
- limit - 몇개의 이미지를 가져올 것인가를 지정
- output_dir - 디렉토리를 지정해 이미지를 담는다.
- dataset()_split() - 크롤링된 데이터중 학습용 데이터로 사용할 데이터 개수를 지정
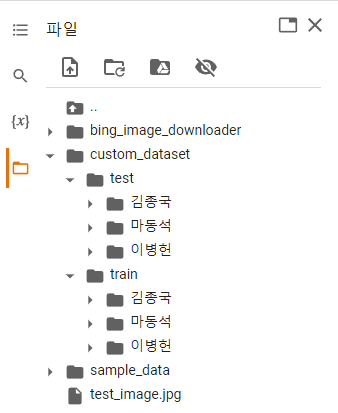
40개의 인물 데이터를 수집한 뒤에는 custom_dataset 폴더에
30개의 학습용 데이터셋과 10개의 검증용 데이터셋으로 구성한다.
PyTorch를 이용한 전이학습(Transfer Learning)
Pytorch를 이용해 인공지능 모델을 학습한다.
앞서 말한 것처럼 우리는 이미 학습이 잘 되어있는 하나의 네트워크를 다운로드해서
그 네트워크의 앞쪽 레이어만 가져온 뒤 우리의 네트워크를 우리의 데이터셋에 대해 다시 학습함으로써
각 인물들에 대해 잘 분류할 수 있는 하나의 네트워크를 만든다.
따라서 가장 먼저 학습을 위해 필요한 라이브러리를 불러온다.
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
from torchvision import datasets, models, transforms
import numpy as np
import time
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") # device 객체gpu를 이용해서 학습을 진행하고 평가를 진행할 것이므로 device 객체를 초기화한다.
데이터 전처리 진행
# 데이터셋을 불러올 때 사용할 변형(transformation) 객체 정의
transforms_train = transforms.Compose([
transforms.Resize((224, 224)),
transforms.RandomHorizontalFlip(), # 데이터 증진(augmentation)
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) # 정규화(normalization)
])
transforms_test = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
data_dir = './custom_dataset'
train_datasets = datasets.ImageFolder(os.path.join(data_dir, 'train'), transforms_train)
test_datasets = datasets.ImageFolder(os.path.join(data_dir, 'test'), transforms_test)
train_dataloader = torch.utils.data.DataLoader(train_datasets, batch_size=4, shuffle=True, num_workers=4)
test_dataloader = torch.utils.data.DataLoader(test_datasets, batch_size=4, shuffle=True, num_workers=4)
print('학습 데이터셋 크기:', len(train_datasets))
print('테스트 데이터셋 크기:', len(test_datasets))
class_names = train_datasets.classes
print('클래스:', class_names)데이터의 가공 과정은 특히 이미지 도메인에서 모델의 성능 향상에 큰 도움이 될 수 있다.
따라서 transformation 객체를 정의하는데
학습 데이터를 불러올 때는 224 x 224 크기로 해상도를 맞추어 준 뒤
데이터 증진 목적으로 이미지를 확률적으로 좌우반전 수행할 수 있도록 해준다.
Pytorch의 tensor 객체로 바꿔준 뒤 데이터의 정규화를 거친다.
이후 평가 목적으로 실제 테스트 데이터를 불러와서 테스트를 진행할 때에 대한 transformation 객체도 정의한다.
imageFolder 라이브러리를 사용하여 각각 학습 데이터와 테스트 데이터를 불러온 뒤
전체 데이터를 학습하는 과정에서 DataLoader를 이용해 필요한 만큼 데이터를 꺼내서 모델에 넣을 수 있도록 만든다.
이미지 시각화
def imshow(input, title):
# torch.Tensor를 numpy 객체로 변환
input = input.numpy().transpose((1, 2, 0))
# 이미지 정규화 해제하기
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
input = std * input + mean
input = np.clip(input, 0, 1)
# 이미지 출력
plt.imshow(input)
plt.title(title)
plt.show()
# 학습 데이터를 배치 단위로 불러오기
iterator = iter(train_dataloader)
# 현재 배치를 이용해 격자 형태의 이미지를 만들어 시각화
inputs, classes = next(iterator)
out = torchvision.utils.make_grid(inputs)
imshow(out, title=[class_names[x] for x in classes])라이브러리가 정상적으로 불러졌는지 확인하기 위해 이미지 시각화 라이브러리를 사용한다.
하나의 torch.Tensor 객체를 화면에 출력하기 위해서는 matplotlib 라이브러리를 사용할 수 있다.
기본적으로 matplotlib 라이브러리는 numpy 객체를 입력으로 받기 때문에
이러한 tensor를 우선 numpy로 바꿔준 이후
pytorch의 경우에는 배치, 채널, 높이, 너비 순서대로 데이터가 구성되기 때문에
축에 대해서도 채널 값이 가장 뒤쪽으로 올 수 있도록 바꿔줄 필요가 있다.
결과적으로 정규화를 해제한 이후 matplotlib를 이용해 해당 이미지를 출력할 수 있다.
그리고 간단하게 배치 하나만큼의 학습 데이터를 불러온 뒤에 이를 시각화 해본다.

현재 학습 데이터에 포함된 이미지에 대해서 각각의 이미지와
그에 해당하는 클래스가 잘 나오는 것을 확인할 수 있다.
CNN 딥러닝 모델 객체 초기화
model = models.resnet34(pretrained=True)
num_features = model.fc.in_features
# 전이 학습(transfer learning): 모델의 출력 뉴런 수를 3개로 교체하여 마지막 레이어 다시 학습
model.fc = nn.Linear(num_features, 3)
model = model.to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)전이학습을 이용할 것이기 때문에 이미 학습 되어있는 하나의 네트워크를 불러온 뒤
그 네트워크의 가장 마지막 레이어만 별도의 Linear 레이어로 바꿔치기 한 뒤 학습을 진행할 것이다.
우리가 새롭게 학습할 모델에서는 파이널 레이어에서 나오는 출력 클래스의 개수가 3개이므로
모델의 출력 뉴런 수를 3개로 교체해서 학습을 수행할 수 있도록 한다.
학습할 모델 또한 초기화를 진행하고 학습을 진행한다.
학습 진행
num_epochs = 50
model.train()
start_time = time.time()
# 전체 반복(epoch) 수 만큼 반복하며
for epoch in range(num_epochs):
running_loss = 0.
running_corrects = 0
# 배치 단위로 학습 데이터 불러오기
for inputs, labels in train_dataloader:
inputs = inputs.to(device)
labels = labels.to(device)
# 모델에 입력(forward)하고 결과 계산
optimizer.zero_grad()
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
loss = criterion(outputs, labels)
# 역전파를 통해 기울기(gradient) 계산 및 학습 진행
loss.backward()
optimizer.step()
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
epoch_loss = running_loss / len(train_datasets)
epoch_acc = running_corrects / len(train_datasets) * 100.
# 학습 과정 중에 결과 출력
print('#{} Loss: {:.4f} Acc: {:.4f}% Time: {:.4f}s'.format(epoch, epoch_loss, epoch_acc, time.time() - start_time))총 50 epochs 만큼 반복해서 전체 데이터셋에 대하여 학습을 진행할 것이다.
train_dataloader는 매번 배치 사이즈만큼 네트워크에 입력을 넣을 수 있도록 데이터를 로드해온다.
train_dataloader를 이용해 매번 이미지와 그에 해당하는 레이블을 가져와 학습을 진행한다.
optimizer를 이용해 전체 모델의 파라미터를 업데이트한다.
먼저 모델의 입력값을 주기 전에 optimizer를 이용해서 전체 gradient 값을 초기화한 뒤에 모델에 넣어주고
cross entropy loss를 이용해서 실제 정답과 output 값이 유사한 값을 가질 수 있는 형태로
그러한 방향으로 모델을 업데이트하기 위해서 역전파를 수행하고
그렇게 구해진 각 모델의 가중치에 대한 gradient 값을 이용해 이 optimizer를 이용해 업데이트를 수행한다.
그래서 결과적으로 우리 모델은 이러한 학습 데이터에 맞도록 좋은 성능이 나오도록 학습이 이루어진다.
학습된 모델 평가
model.eval()
start_time = time.time()
with torch.no_grad():
running_loss = 0.
running_corrects = 0
for inputs, labels in test_dataloader:
inputs = inputs.to(device)
labels = labels.to(device)
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
loss = criterion(outputs, labels)
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
# 한 배치의 첫 번째 이미지에 대하여 결과 시각화
print(f'[예측 결과: {class_names[preds[0]]}] (실제 정답: {class_names[labels.data[0]]})')
imshow(inputs.cpu().data[0], title='예측 결과: ' + class_names[preds[0]])
epoch_loss = running_loss / len(test_datasets)
epoch_acc = running_corrects / len(test_datasets) * 100.
print('[Test Phase] Loss: {:.4f} Acc: {:.4f}% Time: {:.4f}s'.format(epoch_loss, epoch_acc, time.time() - start_time))학습이 완료되면 실제로 학습된 모델이 얼마나 잘 동작하는지 평가하기 위해서
테스트 데이터를 이용해 평가를 진행한다.
이때 테스트 데이터셋은 우리가 학습을 진행할 때 한번도 본적이 없는 이미지일 확률이 높기 때문에
실제 모델을 테스트하기 위한 목적으로 적합하다.
또한 각각의 배치마다 첫번째 이미지에 대해서만 시각화할 수 있도록한다.
그래서 매 배치마다 첫번째 이미지와 그에 대한 예측 결과를 출력하는 방식으로 전체 배치를 확인한뒤
결과적으로 전체 이미지에 대해서 총 몇퍼센트의 정확도를 보이는지 확인할 수 있다.
