
- 📌 HTTP 관련 질문
- 📌 HTTP 버전
- 📌 웹브라우저에 google.com 치면 일어나는 과정
- 📌 OS 스레드, 프로세스 차이(멀티 스레드와 멀티 프로세스 차이, PCB)
- 📌 DB 트랙잭션과 트랙잭션 특성 4가지
- 📌 OS 데드락, 데드락 조건 4가지, 동기화(뮤텍스, 세마포어, 모니터, 스핀락, 어토믹 설명)
- 📌 언어관련 지식
- 📌 TCP vs UDP (TCP, UDP 특성)
- 📌 세그멘테이션, 페이징 (내부단편화, 외부단편화)
- 📌 DB 인덱스, 인덱스 거는 이유, 인덱스에 왜 해시보다 B-Tree를 쓰는지?
- 📌 메모리 구조/스택/힙/데이터/코드 영역
- 📌 (자료구조 질문) 맵 vs 해쉬맵 / 리스트 vs 배열(어레이) / 스택 vs 큐 차이
- 📌 정렬 종류, 퀵소트 설명 (추가적인 손코딩)
- 📌 OSI 계층 말하기(각각 알려진 유명 프로토콜)
- 📌 DB 정규화, 비정규화(역정규화)
- 📌 DB 트랜잭션 격리 수준
📌 HTTP 관련 질문
HTTP, HTTPS(TLS(SSL))/HTTP 1.1 2.0 3.0/ HTTP RESTful / HTTP 응답코드
HTTP : Hypertext Transfer Protocol, 서버와 클라이언트가 요청(Request)과 응답(Response) 형식으로 인터넷에서 데이터를 주고 받을 수 있는 프로토콜
HTTPS(TLS(SSL)) : HyperText Transfer Protocol over Secure Socket Layer, SSL/TLS 계층을 추가하여 클라이언트와 서버 사이에 오가는 모든 HTTP 프로토콜 메세지를 암호화하여 통신하는 프로토콜이다.
📌 HTTP 버전
HTTP/1.1
1. Persistent Connection : 지정한 timeout 동안 커넥션을 닫지 않는 방식
2. 파이프라이닝 기법 : 하나의 커넥션에서 응답을 기다리지 않고 순차적인 여러 요청을 연속적으로 보내 그 순서에 맞춰 응답을 받는 방식 → Head Of Line Blocking 문제 발생
Head Of Line Blocking 문제 : 연속된 요청, 응답일 경우에는 Header가 중복됨에도 계속 Header를 표기함으로써 리소스가 낭비된다.
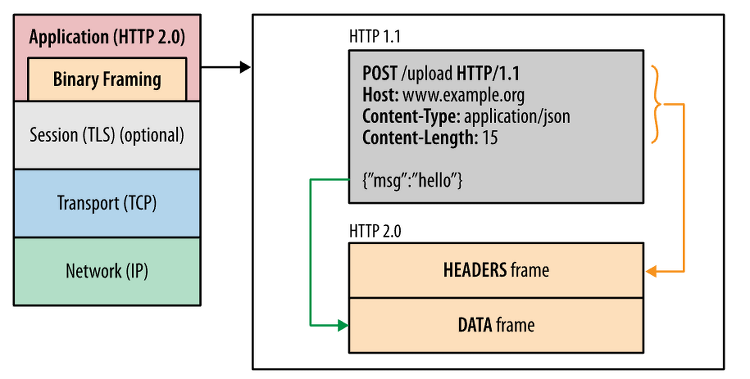
HTTP/2.0

1. 바이너리 프레이밍 계층 사용 : 파싱, 전송 속도 향상, 오류 발생 가능성 저하
2. 멀티플렉싱 스트림을 사용한다.
하나의 TCP 연결 내 다수의 독립적 스트림을 동시 처리하여 송수신하는 것으로, 하나의 스트림의 패킷이 손상되어도 나머지 스트림에 영향을 주지 않으며 Handshake 오버헤드가 감소한다.
요청이 연결 상에서 다중화 되므로 HOL(Head Of Line) Blocking이 발생하지 않는다.
3. Server Push를 사용해 클라이언트가 별도의 요청을 하지 않고도 리소스를 자동으로 전송해준다.
예시로, HTML에 포함된 CSS, JS 파일을 클라이언트가 별도로 요청하지 않아도 서버에서 자동으로 같이 전송해준다.
4. Stream Prioritization :리소스 간 우선 순위 설정 가능
5. Header Compression : Static Dynamic Table 개념 도입 + 중복되지 않은 데이터를 허프만 인코딩 해서 압축 → 헤더의 크기(약 85% 정도 줄어듦)를 줄여 페이지 로드 시간을 감소시킴
HTTP/3.0
TCP가 아닌 UDP를 사용한다는 것이다.
엄밀히 말하면 HTTP/3.0은 QUIC라는 프로토콜 위에서 돌아가는 HTTP인데, QUIC는 Quick UDP Internet Connection의 약자로 UDP를 사용하는 프로토콜이다.
TCP는 3-way handshake 및 4-way handshake 등의 오버헤드와 HOLB 등의 문제를 피할 수 없다.
QUIC는 TCP handshake 과정을 최적화하는 것에 초점을 맞추어 설계되었다.
UDP는 데이터그램 방식을 사용하는 프로토콜이기에 각각의 패킷 간 순서가 존재하지 않는 독립적인 패킷이다.
UDP는 TCP에 비해 헤더가 많이 비어있기 때문에, 커스터마이징 할 수있는 여지가 있고 이를 이용해 개발자가 구현을 어떻게 하느냐에 따라 신뢰성을 확보할 수 있다.
QUIC란 ?
1. 구글에서 만든 전송 계층 프로토콜 (현재 구글 관련 제품 대부분의 기본 프로토콜)
2. UDP 기반으로 설계되어 있다.
TCP의 헤더 길이나 복잡한 알고리즘으로 인한 latency를 방지하기 위해 + UDP는 데이터 전송에 집중한 설계이고 별도 기능 없이 원하는 기능만 구현할 수 있기 때문에
3. 연결 지연 감소
첫 연결 설정에서 필요한 정보와 함께 데이터를 전송(1RTT) → 연결 성공 시 설정을 캐싱하여 다음 연결 때 3-way handshake 없이 바로 데이터 전송이 가능하다. (connection UUID를 사용한다.)
📌 HTTP 응답 코드
- 1xx (정보) : 요청을 받았으며 프로세스를 계속 진행한다.
- 2xx(성공) : 요청을 성공적으로 받았으며 인식했고 수용하였다.
- 3xx(리다이렉션) : 요청 완료를 위해 추가 작업 조치가 필요하다.
- 4xx(클라이언트 오류) : 요청의 문법이 잘못되었거나 요청을 처리할 수 없다.
- 5xx(서버 오류) : 서버가 명백히 유효한 요청에 대한 충족을 실패했다.
자주 접하는 HTTP 응답 코드
301 Moved Permanently
이 응답 코드는 요청한 리소스의 URI가 변경되었음을 의미한다. 새로운 URI가 응답에서 아마도 주어질 수 있다.
302 Temporarily Moved
요청한 리소스의 URI가 일시적으로 변경되었음을 의미한다.
새롭게 변경된 URI는 나중에 만들어질 수 있다. 그러므로, 클라이언트는 향후의 요청도 반드시 동일한 URI로 해야한다.
403 Forbidden
클라이언트는 콘텐츠에 접근할 권리를 가지고 있지 않다. 예를 들어, 그들은 미승인되어 서버는 거절을 위한 적절한 응답을 보낸다. 401과 다른 점은 서버가 클라이언트가 누구인지 알고 있다.
404 Not Found
서버는 요청받은 리소스를 찾을 수 없다. 브라우저에서는 알려지지 않은 URL을 의미한다.
이것은 API에서 종점은 적절하지만 리소스 자체가 존재하지 않음을 의미할 수 있다.
500 Internal Server Error
웹 사이트 서버에 문제가 있음을 의미하지만 서버는 정확한 문제에 대해 더 구체적으로 설명할 수 없다.
501 Not Implemented
서버가 요청을 이행하는 데 필요한 기능을 지원하지 않음을 나타낸다.
502 Bad Gateway
서버가 게이트웨이로부터 잘못된 응답을 수신했음을 의미한다.
인터넷상의 서버가 다른 서버로부터 유효하지 않은 응답을 받은 경우 발생한다.
504 Gateway Tiimeout
웹 페이지를 로드하거나 브라우저에서 다른 요청을 채우려는 동안 한 서버가 액세스하고 있는 서버에서 적시에 응답을 받지 못했음을 의미한다.
이 오류 응답은 서버가 게이트웨이 역할을 하고 있으며 적시에 응답을 받을 수 없을 경우 주어진다.
이 오류는 대게 인터넷상의 서버 간의 네트워크 오류이거나 실제 서버의 문제이다.
컴퓨터, 장치 또는 인터넷 연결의 문제가 아닐 수 있다.
📌 웹브라우저에 google.com 치면 일어나는 과정
- 사용자가 웹 브라우저를 통해 google.com을 입력하면 URL 주소 중 도메인 네임 부분을 DNS 서버에서 검색한다.
- DNS 서버에서 해당 도메인 네임에 해당하는 IP 주소를 찾아 사용자가 입력한 URL 정보와 함께 전달한다.
- 브라우저는 HTTP 프로토콜을 사용하여 request 메세지를 생성하고 HTTP 요청 메세지는 TCP/IP 프로토콜을 사용하여 서버로 전송된다.
- 서버는 특정한 포맷(JSON, XML, HTML)으로 reponse 메세지를 생성하여 다시 브라우저에게 데이터를 전송한다.
- 브라우저는 response를 받아 파싱하여 화면에 렌더링한다.
브라우저에 google.com을 치면 무슨 일이 일어날까? (아니, 진짜로) - 네트워크편
기술 면접을 가게 되면 종종 듣게 되는 면접 질문입니다. 일반적으론 DNS, HTTPS에 대한 기본적인 작동 방식을 알고 있고 그걸 설명할 수 있는지 묻는 간단한 질문이고, 실제로도 그렇게 대답하면
velog.io
📌 OS 스레드, 프로세스 차이(멀티 스레드와 멀티 프로세스 차이, PCB)
프로세스
컴퓨터의 메모리 영역에 올려 연속적으로 실행되고 있는 프로그램으로 최소 한개 이상의 스레드를 가진다.
운영 체제로부터 시스템 자원을 할당받는 작업의 단위이다.
스레드
프로세스가 할당받은 자원을 이용하는 실행 단위로 CPU 입장에서는 최소 작업 단위이다.
스레드는 프로세스 내에서 별도의 register와 stack만 따로 할당받고 Code, Data, Heap 영역을 공유한다.
멀티 프로세스
여러개의 프로세스가 같은 프로그램을 동시에 병렬처리 하는 것
멀티 스레드
하나의 응용프로그램을 여러개의 스레드로 구성하고 각 스레드가 하나의 작업을 처리하도록 하는 것
즉, 프로그램을 여러개 실행하는 것 보다 하나의 프로그램 안에서 여러 작업을 해결하는 것
| 차이점 | 프로세스 | 스레드 |
| 정의 | 실행 중인 프로그램 | 프로세스의 실행 단위 |
| 생성 / 종료 시간 | 많은 시간 소요 | 적은 시간 소요 |
| 컨텍스트 전환 | 많은 시간 소요 | 적은 시간 소요 |
| 상호 작용 | IPC 사용 | 공유 메모리 사용 |
| 자원 소모 | 많음 | 적음 |
| 독립성 | 각각 독립적 | 스택만 독립적이고 이외에는 공유 |
📌 PCB (Process Control Block)
운영체제가 프로세스를 제어하기 위해 정보를 저장해 놓는 곳으로, 프로세스의 상태 정보를 저장하는 구조체이다.
프로세스 상태 관리와 Context Switching을 위해 필요하다.
PCB는 프로세스 생성 시 만들어지며 주기억장치에 유지된다.
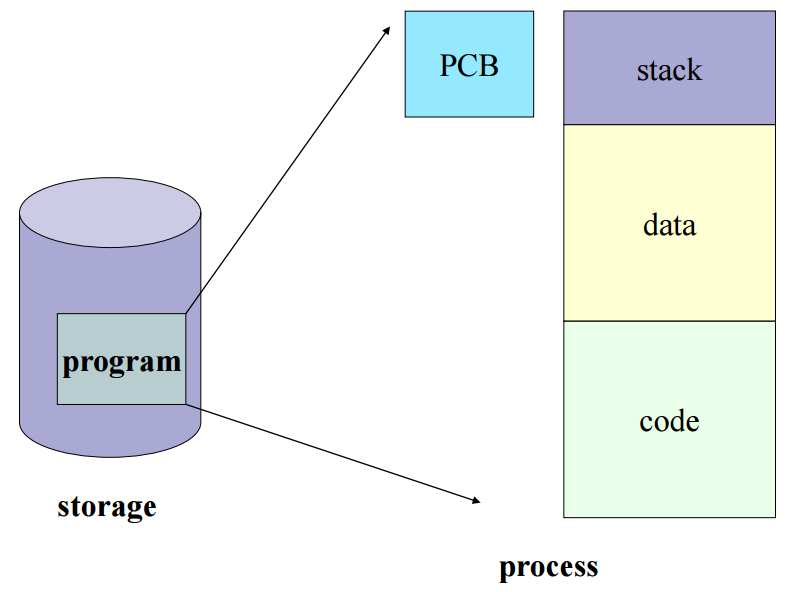
프로그램 실행 → 프로세스 생성 → 프로세스 주소 공간 생성 → 이 프로세스의 메타 데이터들이 PCB에 저장
📌 DB 트랙잭션과 트랙잭션 특성 4가지
트랜잭션이란 ?
데이터베이스의 상태를 변화시키기 위해 수행하는 작업 단위 또는 한꺼번에 모두 수행되어야 할 일련의 연산
트랜잭션 특성 ACID
- Atomicity(원자성) : 트랜잭션의 연산은 데이터베이스에 모두 반영되든지 아니면 전혀 반영되지 않아야 한다. 어느 하나라도 오류가 발생하면 트랜잭션 전부가 취소된다.
- Consistency(일관성) : 하나의 트랜잭션 이전과 이후 데이터베이스의 상태는 이전과 같이 유효해야 한다.
- Isolation(독립성, 격리성) : 둘 이상의 트랜잭션이 동시에 병행 실행되고 있을 때 어떤 트랜잭션도 다른 트랜잭션 연산에 끼어들 수 없다.
- Durability(영속성, 지속성) : 성공적으로 완료된 트랜잭션의 결과는 시스템이 고장나더라도 영구적으로 반영된다.
📌 OS 데드락, 데드락 조건 4가지, 동기화(뮤텍스, 세마포어, 모니터, 스핀락, 어토믹 설명)
📌 DeadLock (데드락)이란 ?
둘 이상의 프로세스가 다른 프로세스가 점유하고 있는 자원을 서로 기다릴 때 무한 대기에 빠지는 현상
DeadLock 발생 조건
발생 조건 4가지가 모두 성립해야 데드락이 발생하며 하나라도 성립하지 않으면 해결 가능하다.
1. 상호 배제 (Mutual exclusion)
자원은 한번에 한 프로세스만 사용할 수 있다. 사용중인 자원을 다른 프로세스가 사용하려면 요청한 자원이 해제될 때까지 기다려야 한다.
2. 점유 대기 (Hold and Wait)
최소한 하나의 자원을 점유하고 있으면서 다른 프로세스에 할당되어 사용하고 있는 자원을 추가로 점유하기 위해 대기하는 프로세스가 존재해야 한다.
3. 비선점 (No preemption)
다른 프로세스에 할당된 자원은 사용이 끝날 때까지 강제로 빼앗을 수 없음
4. 순환 대기(Circular wait)
대기 프로세스의 집합에서 순환 형태로 자원을 대기하고 있어야 한다.
📌 뮤텍스(Mutext)
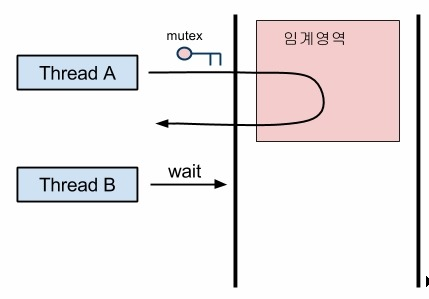
Mutual Exclusion으로 상호 배제라고도 한다.
다중 프로세스들의 공유 리소스에 접근하는 것을 조율하기 위해 locking과 unlocking을 사용한다.
뮤텍스는 이진 세마포어와 같이 초기값을 0과 1로 갖는다.
임계 영역에 들어갈 때 lock을 걸어 다른 프로세스나 쓰레드가 접근하지 못하도록 하고 임계영역에서 나올 때 lock을 해제한다.
mutex = 1;
void lock () {
while (mutex != 1)
{
// mutex 값이 1이 될 때까지 대기
}
// 이 구역에 도착했다는 것은 mutex 값이 1이라는 뜻. 이제 뮤텍스 값을 0으로 만들어 다른 프로세스(혹은 쓰레드)의 접근을 제한
mutex = 0;
}
void unlock() {
// 임계 구역에서 수행을 완료한 프로세스는 다른 프로세스가 접근할 개수 있도록 뮤텍스 값을 1으로 만들어 락을 해제.
mutex = 1;
}
📌 세마포어(Semaphore)란
공유된 자원에 여러 프로세스가 동시에 접근하면 문제가 발생할 수 있다.
이 때 공유된 자원의 데이터는 한번에 하나의 프로세스만 접근할 수 있도록 제한을 둬야 한다.
이를 위해 나온 개념이 '세마 포어'이다. 즉, 세마포어란 멀티 프로그래밍 환경에서 공유 자원에 대한 접근을 제한하는 방법이다.
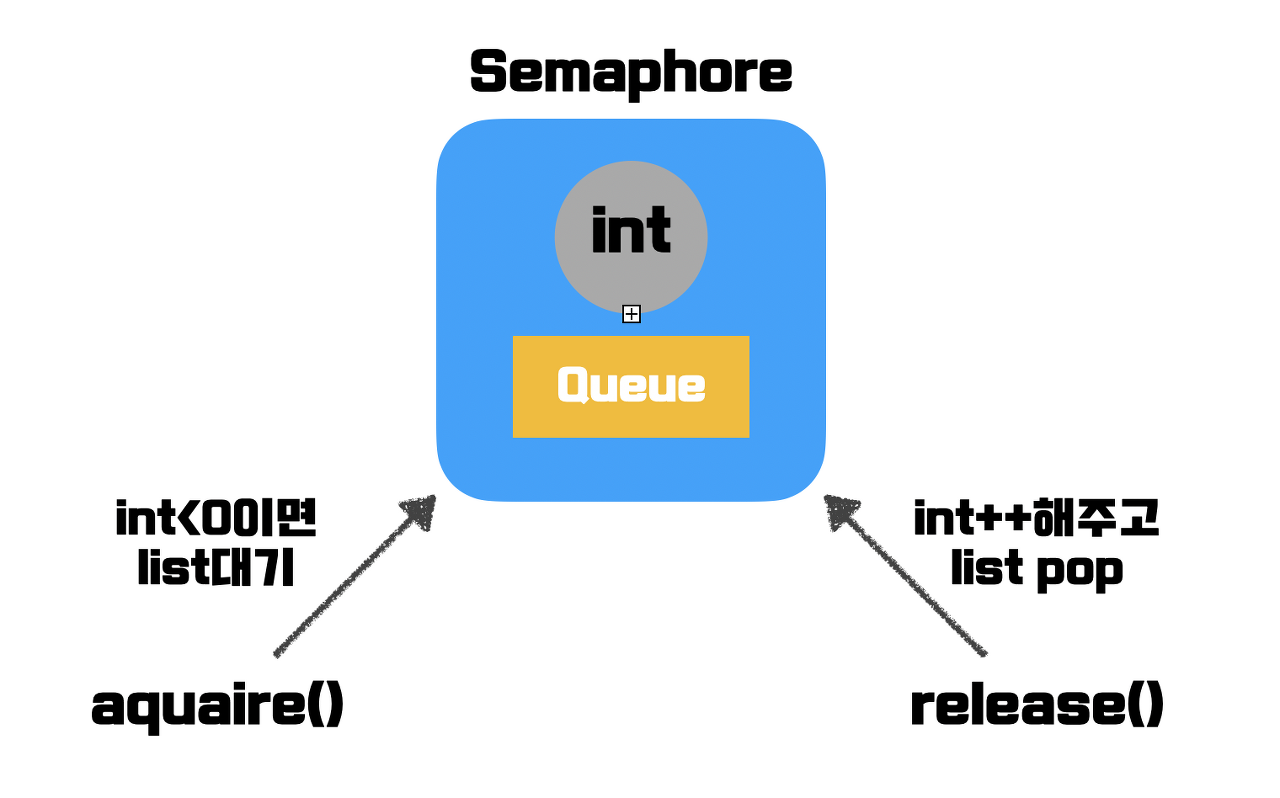
세마포어의 구성 요소는 크게 세마포어 변수, P 동작, V 동작이 있다.
S (세마포어의 변수)
정수 값을 가지는 정적 변수이며, 정수 값은 공유 자원에 접근 가능한 프로세스의 개수를 의미한다.
이때 세마포어 값이 0 또는 1의 값만 만들 수 있다면 (한번에 접근 가능한 프로세스가 1개일 경우) 이진 세마포어라고 하며
2 이상의 값도 가질 수 있는 경우 계수 세마포어라고 한다.
P (try를 의미, acquire())
프로세스가 임계 구역에 들어가기 전에 수행되고(try), 세마포어 값을 감소시킨다.
만일 감소 후 값이 음수가 되면 프로세스를 Ready Queue에 추가한 후 함수를 호출한 프로세스는 Lock이 된다.
즉, 세마포어 값이 0보다 크면 프로세스의 접근을 허용하되 1을 감소하고 난 뒤 값이 0이 되는 순간부터 프로세스 접근을 금지한다.
V (increment를 의미, release())
작업이 끝나고 프로세스나 쓰레드가 임계 구역에서 나갈 때는 세마포어 값을 증가시킨다(increase).
만약 세마포어 값이 음수이면, Ready Queue에 있던 Lock 상태의 프로세스를 하나 꺼내서 임계 구역을 수행할 수 있게 한다.
이때 변수를 수정하는 두 연산(P, V)은 모두 원자성을 만족해야 한다. 한 프로세스나 쓰레드에서 S 값을 변경하는 동안 다른 프로세스나 쓰레드가 동시에 접근해서 변경할 수 없다.
📌 모니터(Monitor)
모니터 등장 배경
추적하기 어려운 Timing Errors가 발생할 수 있다.
예를 들어 바이너리 세마포어를 사용할 시, 각 프로세스들이 wait() → signal() 순서를 지켜야하는데 이를 지키지 않을 경우가 있을 수 있고 그럴 경우 임계 영역에 두개의 프로세스가 동시에 진입하게되는 문제가 있다.
즉, 세마포어는 프로그래머의 실수가 유발될 수 있으므로 이러한 가능성을 최대한 낮춰야 한다.
모니터란 ?
- 프로그래밍 언어 수준에서 동시성을 제어하여 타이밍 오류를 해결한 상호 배제 기법이다.
- 필요한 공유자원을 프로세스에게 할당하는데에 필요한 데이터와 데이터를 처리하는 procedure로 구성된다.
- 모니터에는 한번에 하나의 프로시저만 접근하여 사용 가능하다. 이때 wait()과 signal()을 사용한다.
- 한 프로세스가 특정 모니터의 procedure를 실행 중이면 다른 프로세스들은 이 모니터의 procedure들을 실행하지 못하고 대기 상태에 있게 된다.
📌 스핀락(Spin Lock)이란 ?
Critical Section에 진입 불가할 때 컨텍스트 스위칭을 하지 않고 잠시 루프를 돌면서 재시도를 하는것을 말한다.
임계 영역에 짧은 시간 안에 진입할 수 있는 경우 Context Switching을 제거할 수 있어 효율적이다.
ex) 숫자를 단순히 +1 해주는데 사용되는 락이 있다고 하면 거창하게 Context Switching로 구현할 필요가 없다.
적절한 시간 동안을 외부에서 for or while로 루프를 돌면서 락을 검사하고 처리하는 것이 낫다.→ 즉 임계 영역이 매우 작거나 아주 빨리 처리할 수 있는 경우 스핀락을 쓰게 된다.
📌 어토믹 연산
- 글로벌 자원을 읽고, 수정하고, 다시 되돌리는 이 과정을 가장 작은 단위로 만드는 것이다.
- 즉 한 프로세스의 일련의 모든 연산이 끝날 때까지 다른 프로세스는 그 연산에 대한 어떠한 변화도 할 수 없다.
- 전체 연산 중 어느 하나라도 실패할 경우, 모든 연산은 실패하여, 시스템은 전체 연산이 시작하기 전의 상태로 복구된다.
📌 언어관련 지식
JAVA면 JVM, GC/ JAVA 객체지향, 솔리드, 프로그램 실행의 일련과정
객체지향 vs 절차지향, 오버라이딩 vs 오버로딩, 인터페이스, 추상클래스, 가상함수 등
📌 TCP vs UDP (TCP, UDP 특성)
TCP와 UDP는 TCP/IP의 전송계층에서 사용되는 프로토콜이다.
전송계층은 IP에 의해 전달되는 패킷의 오류를 검사하고 재전송 요구 등의 제어를 담당하는 계층이다.
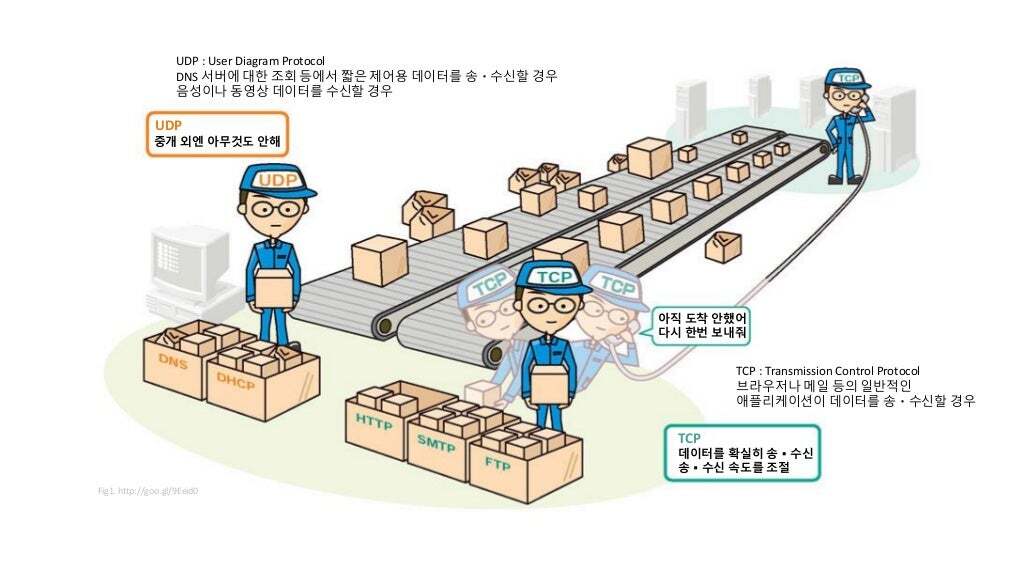
두 프로토콜은 모두 패킷을 한 컴퓨터에서 다른 컴퓨터로 전달해주는 IP 프로토콜을 기반으로 구현되어 있지만, 서로 다른 특징을 가지고 있다.
| 프로토콜 종류 | TCP | UDP |
| 연결 방식 | 연결형 서비스 | 비연결형 서비스 |
| 패킷 교환 방식 | 가상 회선 방식 | 데이터그램 방식 |
| 전송 순서 | 전송 순서 보장 | 전송 순서가 바뀔 수 있음 |
| 수신 여부 확인 | 수신 여부를 확인함 | 수신 여부를 확인하지 않음 |
| 통신 방식 | 1 : 1통신 | 1 : 1 or 1 : N or N : N 통신 |
| 신뢰성 | 높다 | 낮다 |
| 속도 | 느리다 | 빠르다 |
📌 세그멘테이션, 페이징 (내부단편화, 외부단편화)
페이징 : 프로세스를 정확하게 일정한 간격(페이지 단위)로 잘라 메모리에 적재하는 방법 → 내부 단편화 문제 발생
세그멘테이션 : 프로세스를 논리적 단위(세그먼트)로 잘라서 메모리에 적재하는 방법 → 외부 단편화 문제 발생
내부 단편화 : 메모리를 할당할 때 프로세스가 필요한 양보다 더 큰 메모리가 할당되어서 프로세스에서 사용하는 메모리 공간이 낭비되는 상황
외부 단편화 : 메모리가 할당되고 해제되는 작업이 반복적으로 일어날 때 할당된 메모리와 메모리 사이에 사용하지 않는 작은 메모리 공간이 생기는데 총 메모리 공간은 충분하지만 실제로는 할당할 수 없는 상황
📌 DB 인덱스, 인덱스 거는 이유, 인덱스에 왜 해시보다 B-Tree를 쓰는지?
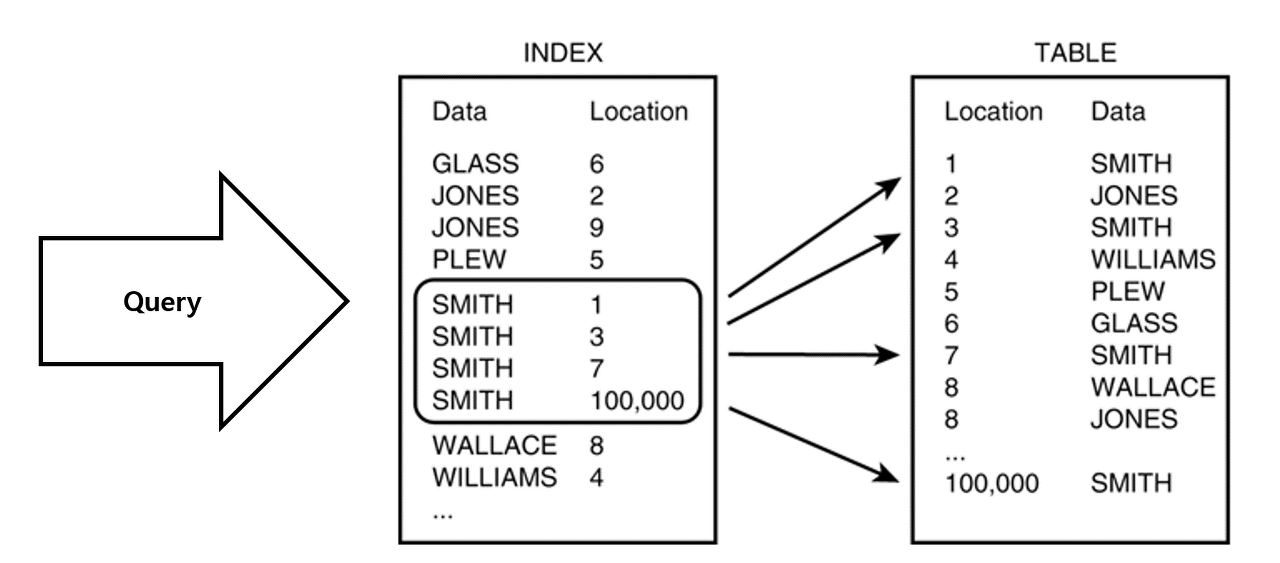
DB 인덱스 : 데이터베이스 테이블에 대한 검색 성능의 속도를 높여주는 자료구조로 특정 컬럼에 인덱스를 생성하면 해당 컬럼의 데이터들을 정렬하여 별도의 공간에 데이터의 물리적 주소와 함께 저장된다.
인덱스를 사용하는 이유 ?
데이터들이 정렬되어 있다는 점은 조건 검색의 영역에서 큰 장점이 된다.
- 조건 검색 where 절의 효율성
- 정렬 order by 절의 효율성
- min, max의 효율적인 처리 가능
인덱스의 단점
인덱스의 가장 큰 문제점은 정렬된 상태를 계속 유지 시켜줘야 한다는 점이다.
레코드 내에 데이터값이 바뀌는 부분이라면 악영향을 미친다.
데이터가 추가되거나 값이 바뀌면 Index 테이블 내의 값들을 다시 정렬해야 하고 Index 테이블과 원본 테이블 두군데에 수정 작업을 해줘야 한다.
DB 인덱스로 B-Tree가 가장 적합한 이유
- 항상 정렬된 상태로 특정 값보다 크고 작은 부등호 연산에 문제가 없다.
- 참조 포인터가 적어 방대한 데이터 양에도 빠른 메모리 접근이 가능하다.
- 데이터 탐색뿐 아니라, 저장, 수정, 삭제에도 항상 O(logN)의 시간 복잡도를 가진다.
📌 메모리 구조/스택/힙/데이터/코드 영역
선언하면 어느쪽에 저장되는지 설명하기
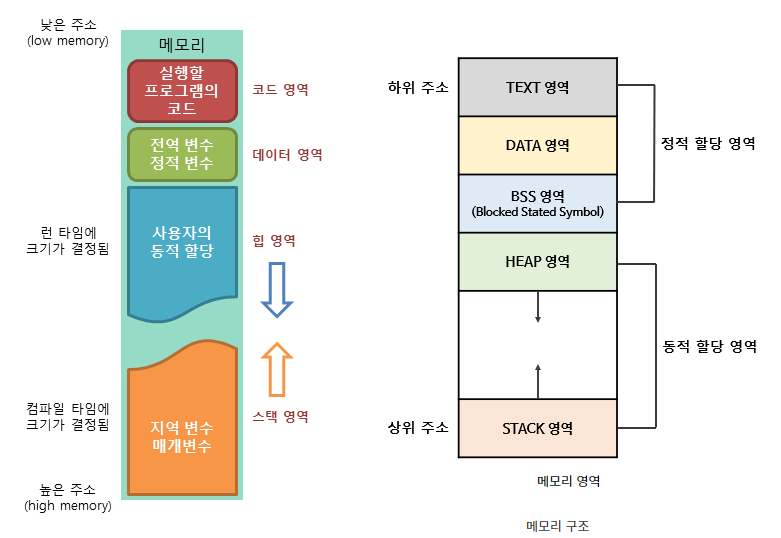
- Code 영역(Text 영역)
실행할 프로그램의 코드나 명령어들이 기계어 형태로 저장되는 영역이다.
CPU는 코드 영역에 저장된 명령어들을 하나씩 처리한다. 프로그램이 시작되고 끝날 때까지 메모리 영역에 유지한다.
- Data 영역
코드에서 선언한 전역 변수와 정적 변수가 저장되는 영역
프로그램이 실행되면서 할당되고 종료되면서 해제한다.- 초기화된 데이터는 data 영역(ROM에 저장)
- 초기화되지 않은 데이터는 bss 영역 (RAM에 저장)
- Stack 영역
프로그램에 의해 사용되는 임시 데이터 영역
함수 안에서 선언된 지역 변수, 매개 변수, 리턴 값등이 저장된다. 함수 호출 시 기록되고 종료되면 해제된다.
메모리 주소는 높은 곳에서 낮은 곳의 방향으로 할당된다. - Heap 영역
프로그래머에 의해 할당되고 해제되는 영역
메모리를 동적으로 할당하고자 할 때 사용되는 메모리 영역
스택과 반대로 메모리 주소가 낮은 곳에서 높은 곳의 방향으로 할당된다.
구역을 나누어 저장하는 이유 ? 효율적인 메모리 사용을 위해
- 코드 Segment : 프로그램 소스 코드 저장
- 데이터 Segment : 전역 변수 저장
- 스택 Segment : 함수, 지역 변수 저장
데이터를 최대한 공유하여 메모리 사용량을 줄여야한다.
Code는 같은 프로그램 자체에서는 모두 같은 내용이기 때문에 따로 관리하여 공유한다.
Stack과 Data를 나눈 이유는 스택 구조의 특성과 전역 변수의 활용성을 위한 것이다.
프로그램의 함수, 지역 변수는 스택에서 실행된다. 따라서 이 함수들 안에서 공통으로 사용하는 "전역 변수"는 따로 지정해두면 메모리를 아낄 수 있다.
📌 (자료구조 질문) 맵 vs 해쉬맵 / 리스트 vs 배열(어레이) / 스택 vs 큐 차이
📌 Map vs HashMap
가장 큰 차이는 특정 키에 대한 값을 찾는 과정에서 Hash_Map은 이름 그대로 Hash Table을 이용해서 키-값 관계를 유지하며 Map 은 Red-black tree 알고리즘을 이용한다.
Map
Map은 Key와 Value를 가진 집합이며 Key는 중복을 허용하지 않는다.
즉, 한개의 Key에 한개의 Value가 매칭된다.
HashMap
HashMap은 Map Interface를 구현한 클래스로서 중복을 허용하지 않는다.
Map의 특징인 Key와 Value의 쌍으로 이루어지며 key 또는 value 값으로써 null 을 허용한다.
📌 List vs Array
리스트는 메모리가 다음 노드를 가리키는 주소값을 가지며 배열은 연속된 메모리 공간에 할당된다.
List
빈틈없이 데이터를 적재하며 원소를 삭제했을 때 삭제된 데이터 뒤 원소를 앞으로 당겨 빈틈없이 연속적으로 위치시킨다.
Array
정해진 크기의 배열에 데이터들을 하나씩 넣는 구조이다.
메모리에 연속적인 공간이 할당되고 random access가 가능하여 검색이 빠르지만 삽입이나 삭제가 크기에서 벗어나게 할 수는 없다.
📌 Stack vs Queue
둘 다 선형 자료 구조의 일종으로 Stack은 LIFO이고 Queue는 FIFO이다.
📌 정렬 종류, 퀵소트 설명 (추가적인 손코딩)
1. 선택 정렬(Selection Sort)
선택된 값과 나머지 데이터중에 비교하여 알맞은 자리를 찾는 정렬
2. 삽입 정렬(Insertion Sort)
데이터 집합을 순회하면서 정렬이 필요한 요소롤 뽑아내어 이를 다시 적당한곳으로 삽입하는 정렬
버블 정렬보다 성능이 좋다.
3. 버블 정렬(Bubble Sort)
인접한 두 수를 비교하여 오름차순 or 내림차순
4. 병합 정렬(Merge Sort)
둘 이상의 부분집합으로 가르고 각 부분집합을 정렬한 다음 부분집합들을 다시 정렬된 형태로 합치는 정렬
분할 정복법을 사용한다.
5. 힙 정렬(Heap Sort)
트리 기반으로 최대 힙 트리 or 최소 힙 트리를 구성해 정렬을 하는 방법
내림차순 정렬을 위해서는 최대 힙을 구성하고 오름차순 정렬을 위해서는 최소 힙을 구성하면 된다.
6. 퀵 정렬(Quick Sort)
데이터 집합내에 임의의 기준(pivot)값을 정하고 해당 피벗으로 집합을 기준으로 두개의 부분 집합으로 나눈다.
한쪽 부분에는 피벗값보다 작은값들만, 다른 한쪽은 큰값들만 넣는다.
더 이상 쪼갤 부분 집합이 없을 때까지 각각의 부분 집합에 대해 피벗/쪼개기를 재귀적으로 적용한다.
7. 기수 정렬(Radix Sort)
낮은 자리수부터 비교해가며 정렬한다. 비교연산을 하지 않아 빠르지만 또 다른 메모리 공간을 필요하다는게 단점
기수 정렬은 낮은 자리수부터 비교하여 정렬해 간다는 것을 기본 개념으로 하는 정렬 알고리즘이다.
기수정렬은 비교 연산을 하지 않으며 정렬 속도가 빠르지만 데이터 전체 크기에 기수 테이블의 크기만한 메모리가 더 필요하다.
📌 OSI 계층 말하기(각각 알려진 유명 프로토콜)
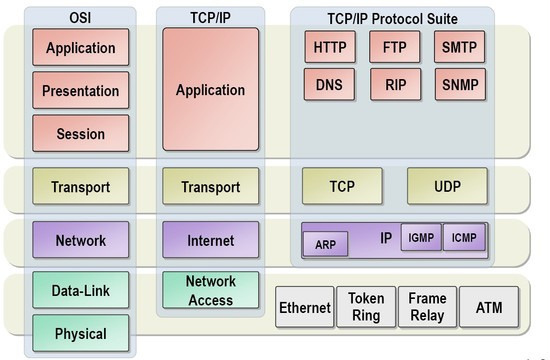
- 물리 계층 : 물리적으로 데이터를 전송하는 역할을 수행
- 데이터 링크 계층 : 물리적 전송 오류를 해결(오류 감지/ 재전송 기능)
- 네트워크 계층 : 올바른 전송 경로를 선택(혼잡 제어 포함)
- 전송 계층 : 송수신 프로세스 사이의 연결 기능을 지원
- 세션 계층 : 대화 개념을 지원하는 상위의 논리적인 연결을 지원
- 표현 계층 : 데이터의 표현 방법
- 압축 : 전송되는 데이터 양
- 암호화 : 전송되는 데이터의 의미
- 응용 계층 : 다양한 응용 환경을 지원
📌 DB 정규화, 비정규화(역정규화)
DB 정규화
DB 정규화의 가장 큰 목표는 테이블 간 중복된 데이터를 허용하지 않는 것이다.
- 데이터의 중복을 없애면서 불필요한 데이터를 최소화시킨다.
- 무결성을 지키고, 이상 현상을 방지한다.
- 테이블 구성을 논리적이고 직관적으로 할 수 있다.
- 데이터베이스 구조의 확장에 용이해진다.
제 1정규화(1NF)
테이블 컬럼이 원자값(하나의 값)을 갖도록 테이블을 분리시키는 것을 말한다.
만족해야 할 조건은 아래와 같다.
- 어떤 릴레이션에 속한 모든 도메인이 원자값만으로 되어 있어야한다.
- 모든 속성에 반복되는 그룹이 나타나지 않는다.
- 기본키를 사용하여 관련 데이터의 각 집합을 고유하게 식별할 수 있어야 한다.
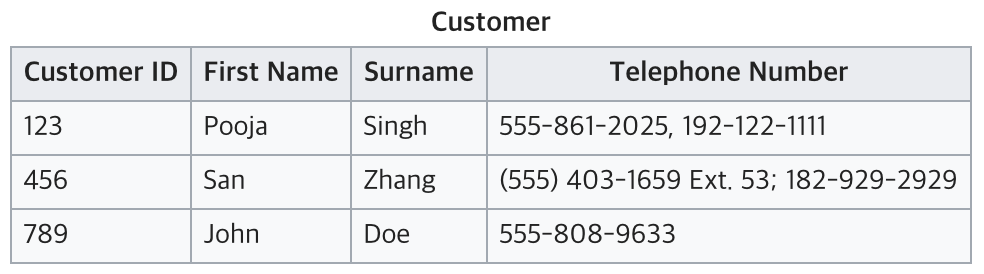
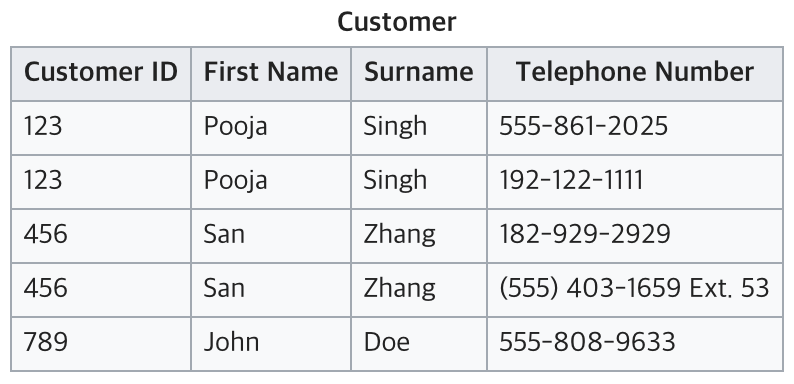
현재 테이블은 전화번호를 여러개 가지고 있어 원자값이 아니다. 따라서 1NF에 맞추기 위해서는 아래와 같이 분리할 수 있다.
제 2정규화(2NF)
테이블의 모든 컬럼이 완전 함수적 종속을 만족해야 한다.
조금 쉽게 말하면 테이블에서 기본키가 복합키(키1, 키2)로 묶여있을 때, 두 키 중 하나의 키만으로 다른 컬럼을 결정지을 수 있으면 안된다.
기본키의 부분 집합 키가 결정자가 되어선 안된다는 것
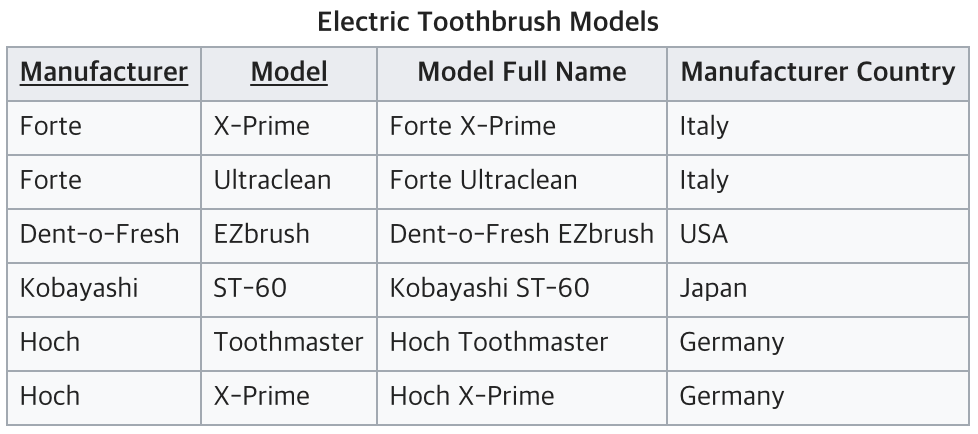
Manufacture과 Model이 키가 되어 Model Full Name을 알 수 있다.
Manufacturer Country는 Manufacturer로 인해 결정된다. (부분 함수 종속)
따라서, Model과 Manufacturer Country는 아무런 연관관계가 없는 상황이다.
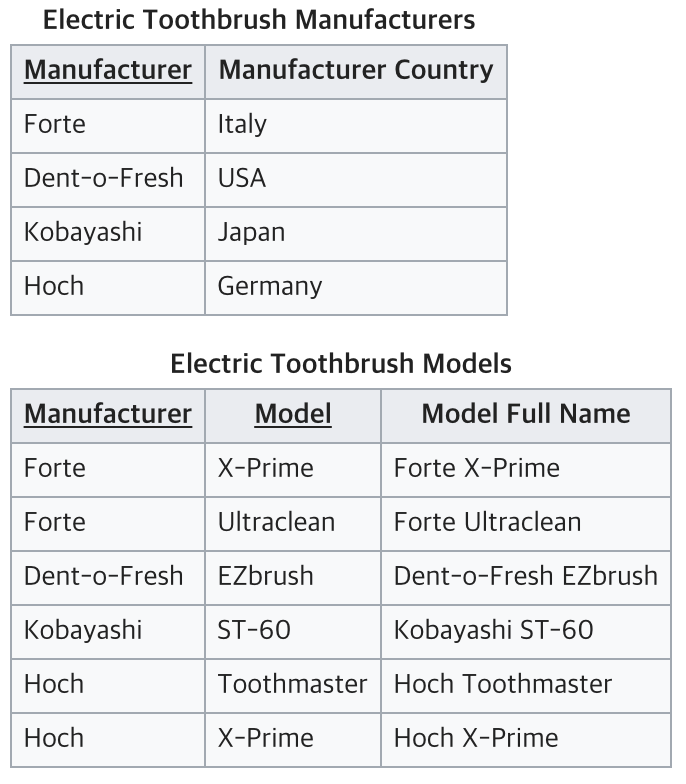
결국 완전 함수적 종속을 충족시키지 못하고 있는 테이블이다. 부분 함수 종속을 해결하기 위해 테이블을 아래와 같이 나눠서 2NF를 만족할 수 있다.
제 3정규화(3NF)
2NF가 진행된 테이블에서 이행적 종속을 없애기 위해 테이블을 분리하는 것이다.
이행적 종속 : A → B, B → C면 A → C가 성립된다
아래 두가지 조건을 만족시켜야 한다.
- 릴레이션이 2NF에 만족한다.
- 기본키가 아닌 속성들은 기본키에 의존한다.
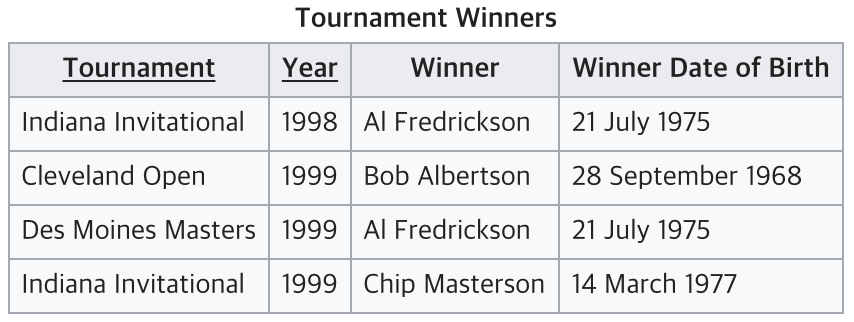
현재 테이블에서는 Tournament와 Year이 기본키다.
Winner는 이 두 복합키를 통해 결정된다.
하지만 Winner Date of Birth는 기본키가 아닌 Winner에 의해 결정되고 있다.
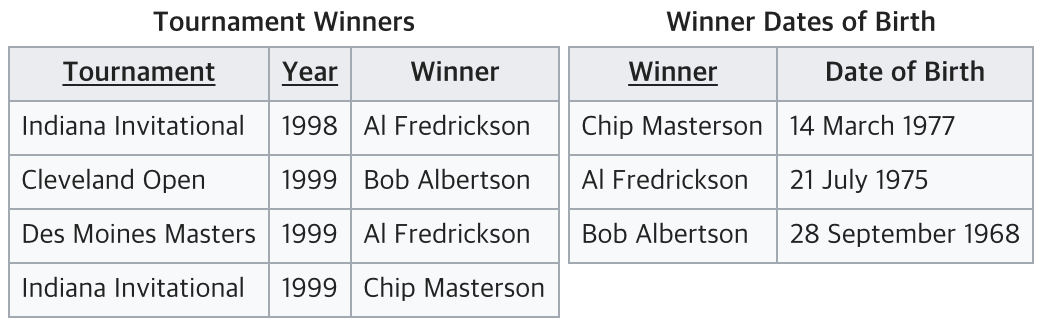
따라서 이는 3NF를 위반하고 있으므로 아래와 같이 분리해야 한다.
📌 DB 트랜잭션 격리 수준
격리 수준이란 ?
트랜잭션에서 일관성 없는 데이터를 허용하도록 하는 수준
격리 수준의 필요성
데이터베이스는 ACID 특징과 같이 트랜잭션이 독립적인 수행을 하도록 한다.
따라서 Locking을 통해 트랜잭션이 DB를 다루는 동안 다른 트랜잭션이 관여하지 못하도록 막는 것이 필요하다.
하지만 무조건 Locking으로 동시에 수행되는 수많은 트랜잭션들을 순서대로 처리하는 방식으로 구현하게 되면 데이터베이스의 성능은 떨어지게 될 것이다.
그렇다고 해서 성능을 높이기 위해 Locking의 범위를 줄인다면 잘못된 값이 처리될 문제가 발생하게 된다.
→ 따라서 최대한 효율적인 Locking 방법이 필요하다.
참고
https://inpa.tistory.com/entry/WEB-%F0%9F%8C%90-HTTP-%EC%83%81%ED%83%9C-%EC%BD%94%EB%93%9C-%EC%A0%95%EB%A6%AC
https://yjm6560.tistory.com/30
https://devahea.github.io/2019/04/30/5G-%EC%B4%88%EC%97%B0%EA%B2%B0%EC%8B%9C%EB%8C%80%EC%97%90-%EC%9B%B9-HTTP%EC%9D%98-%EB%8C%80%EC%95%88%EC%9D%80-QUIC/
https://x-ojm.tistory.com/120
https://gakari.tistory.com/entry/HTTP-20-HTTP-30
https://itnovice1.blogspot.com/2019/08/mutual-exclusion.html
https://velog.io/@hidaehyunlee/TCP-%EC%99%80-UDP-%EC%9D%98-%EC%B0%A8%EC%9D%B4
https://helloinyong.tistory.com/296
https://hyo-ue4study.tistory.com/68
https://gyoogle.dev/blog/computer-science/data-base/Normalization.html
'CS' 카테고리의 다른 글
| 재귀함수의 호출 (+ 스택) (0) | 2022.07.11 |
|---|
영차영차 성장 블로그
포스팅이 좋았다면 "좋아요❤️" 또는 "구독👍🏻" 해주세요!
